
 字号:
小
中
大
字号:
小
中
大
声调基频是一种连续的非线性数据。长期以来,针对基频数据多采用T检验、方差分析等“点对点”的统计方法,但近年来统计工具的不断更新,如线性混合效应模型(linear mixed-effects model)的出现(Baayen et al.,2008),对于声调研究中的传统统计方法提出了较大质疑。
第一、声调的语言学意义。“点对点”分析只能比较不同声调曲线在某个点上的局部基频值,无法反映声调基频的总体高低、斜率以及凹凸程度,因此所得结果与具有语言学意义的声调高低或调型之间并不存在对应关系。此外,由于每个点是分别比较的,因此极有可能出现整条基频曲线中存在非连续性统计显著或不显著的情况,这些非连续性结果的语言学意义值得质疑。
第二、基频数据的数理性质。尽管基频取值是在连续信号中以离散的方式取得的,但这些离散的点具有时间上的先后性,彼此并非独立。而“点对点”比较本质上是将连续的、彼此不独立的时程数据当作彼此独立的离散量来处理。此外,对于时程数据而言,我们不仅要考虑时程上每个点的具体数值,还要考虑数值随着时间而发生的变化,而这种变化是传统“点对点”比较无法兼顾的(Mirman,2014)。
第三、个体差异因素的存在。在采用多个发音人或多实验字的实验中,个体差异是不可回避的问题。个体差异的来源多种多样,但对于这些个体因素,传统的方言学或音系学研究一般鲜有关注,而“点对点”分析(比如方差分析)也只能够在一定程度上兼顾不同来源的个体差异,因此不具有优势。
本文介绍的统计方法——“增长曲线分析”法,能够有效地解决上述弊端。
“增长曲线分析”法是线性混合效应模型家族的一员。近年来,线性混合效应模型在心理语言学研究中已得到了较为广泛的运用,采用线性混合效应模型进行定量研究逐渐成为语言学发展的一大趋势。与传统方差分析等简单线性模型相比,线性混合模型能将各种类型的随机因素统一在同一个模型中考虑(Bates et al.,2015)。而“增长曲线分析”法则是在一般线性混合效应模型的基础上,在自变量中加入时间以及固定变量与时间的交互作用,可表述为如下公式:

除了能够对随机因素进行考察之外,较之传统“点对点”的统计方法来说,“增长曲线分析”法更重要的优势在其能较好地与声调的语言学意义进行关联,而这种关联由自变量中的“时间”一项来实现。
概括来说,该方法就是把每条随时间变化的基频曲线当作一个整体去看待,通过用“正交多项式(orthogonal polynomial)”函数拟合曲线的方式,将曲线分解成彼此独立的时间分量(本文用“时间n”来表示时间分量)。由于不同次方的时间分量分别代表了曲线形状的不同特征,不同时间分量前的系数差异则因此可以量化为基频曲线在不同特征上的差异。比如,零次方分量(“时间0”)代表均值,对应声调基频曲线的总体高低;一次方分量(“时间1”)代表斜率,对应基频的升降;二次方分量(“时间2”)代表曲线形状,对应声调的凹凸程度等。下图展示了不同时间分量的系数值分别对曲线形状的影响,其中1)-5)分别为零次方至四次方。
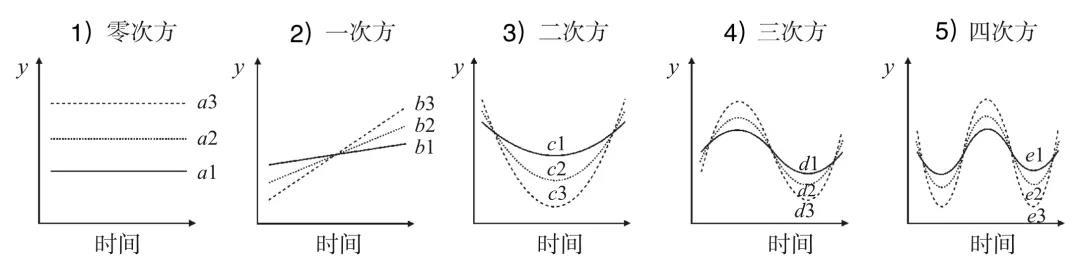
图:不同时间分量值与曲线形状的关系示意图(根据Mirman,2014书中图3.6重绘)。1):零次方系;2):一次方系数;3):二次方系数;4):三次方系数;5):四次方系数。图中各时间系数下标数字越大,系数值越大。
当一条平行于时间轴的直线用正交多项式拟合时,只具有一个零次方的时间分量。可用公式表示为:时间=系数a·时间0。在正交多项式中,零次方分量(“时间0”)代表直线的总体平均值,系数a则为零次方时间分量的系数,系数的大小决定了直线的高低,如上图1),通常对应声调基频曲线的总体高低。
一条不平行于时间轴的直线用正交多项式拟合,则不仅需要“时间0”所表示的高低分量,还需要一个代表直线方向的一次方时间分量(“时间1”)。可用公式表示为:时间=系数a·时间0+系数b·时间1。这里的系数b为一次方时间分量的系数,系数的大小决定了直线的斜率,如上图2),通常对应声调基频曲线的变化方向,也就是升降。
而一条单峰或单谷的U型(或倒U型)曲线就比直线多了一个代表曲线凹凸程度的二次方时间分量(“时间2”)。可用公式表示为:时间=系数a·时间0+系数b·时间1+系数c·时间2。其中,系数c是二次方时间分量的系数,其大小决定了该U型曲线峰或谷的拱度,如上图3),通常对应声调曲线的凹凸程度。
同理,同时具有峰和谷的S型曲线则比U型曲线多了一个三次方的时间分量(“时间3”)。可用公式表示为:时间=系数a·时间0+系数b·时间1+系数c·时间2+系数d·时间3。系数d是三次方时间分量的系数,其大小决定了S型曲线的凹凸程度,如上图4)。
以此类推,如果在此基础上再增加一个四次方时间分量则可以拟合出一条双峰或双谷的W型曲线,可用公式表示为:时间=系数a·时间0+系数b·时间1+系数c·时间2+系数d·时间3+系数e·时间4。系数e调节W型曲线的凹凸程度,如上图5)。
为了保证统计模型的最优化,建模时时间分量的个数应该根据实际曲线的形状来决定。比如对于声调而言,大部分复杂的基频曲线一般只有一个峰值或谷值(如曲折调,即U型),因此通常只需要考虑至二次方的时间分量即可。通过这种方法,任何声调基频曲线皆可分解成均值、斜率和凹凸程度等特征系数。研究者通过对比不同特征系数,从而刻画曲线间的异同。这种统计方法不仅能够较有效地解决传统“点对点”统计方法所带来的诸多弊端,还能将声调数据中的个体差异考虑在内。
本文还通过两个具体实例研究——黎里方言单字调和天津方言两字组连调,展示了“增长曲线分析”法在解决汉语方言声调研究争议问题的有效性。这两个问题在汉语方言学界以及理论音系学界一直都存在较多争议。而“增长曲线分析”法能够较有效地帮助解决这两个问题。关于两个案例各自的问题缘起与具体研究方法和步骤,请详见原文。由两个案例可见,采用“增长曲线分析”法不仅可以用于讨论两条基频曲线是否已经合并(案例一),也能够辅助甄别发生连读变调的声调组合(案例二)。由两个案例可见,相对于传统分析方法,“增长曲线分析”法具有更大优势。此外,文章也在附录部分详细描述了利用“增长曲线分析”法对数据进行建模的一般方法,以及两个具体案例研究中的统计建模方法和最终模型。关于“增长曲线分析”法的更多操作细节,读者可参考Mirman(2014)。
参考文献
Baayen, Harald, Doug Davidson, and Douglas Bates 2008 Mixed-Effects Modeling with Crossed Random Effects for Subjects and Items. Journal of Memory and Language 59: 390–412.
Bates, Douglas, Reinhold Kliegl, Shravan Vasishth, and Harald Baayen 2015 Parsimonious Mixed Models. ArXiv. https://doi.org/arXiv:1506.04967.
Mirman, Daniel 2014 Growth Curve Analysis and Visualization Using R. Boca Raton: Taylor & Francis Group.
原文刊于《中国语文》2020年第5期
作者简介
李倩,女,中国社会科学院语言研究所副研究员。博士毕业于荷兰莱顿大学语言学中心,主要研究方向为语音学和心理语言学。曾在Journal of Phonetics、Journal of the International Phonetic Association 、Journal of East Asian Linguistics等刊物发表学术论文,主持国家社科基金青年项目1项。

史濛辉,男,复旦大学现代语言学研究院副研究员。博士毕业于荷兰莱顿大学语言学中心,研究方向为语音学、方言学和语言变异。曾在The Journal of the Acoustical Society of America、Journal of the International Phonetic Association、《中国语文》《语言学论丛》等刊物上发表学术论文。

陈轶亚,女,荷兰莱顿大学语言学中心教授,法国国家科学院东亚语言研究所联合研究员,博士生导师,研究方向为语音学、心理语言学、方言学等。荷兰研究理事会(NWO)、荷兰皇家科学院(KNAW)、欧洲研究理事会(ERC)等诸多研究机构重大项目主持人。

